GatsbyでMarkdownをソースにするブログを作ったらサイト内検索が欲しくなった。
検索自前で作るの面倒…とはいえ検索がないブログは不便なんだよなあ…。
他所に頼るならお手軽なGoogleのカスタム検索か、有能なAlgoliaを使うのが手っ取り早いが、Googleのカスタム検索はUIがカスタムしづらく、Algoliaは有料プランだとお値段が結構高い。
結果自前で渋々実装しなければならないケースもままあると思う。
で、実際にサイト内検索の実装をやってみた結果このメモが生まれたわけだが、これくらいの手間をかけないと日本語の検索として満足な動作を得られなかった。
やったこと
- Markdownからキーワードを抽出したJSONを生成
- キーワード抽出はKuromoji.jsを利用する
- 最近の単語に反応させるため mecab-ipadic-neologd の辞書を追加
- mecab辞書をkuromoji辞書に変換する
- ひらがなとかも登録しておく
- Gatsby Node APIでJSONをpublicにコピー
- Gatsby Browser API でキーワードをFlexsearchに登録
- Searchコンポーネントで検索を実行、結果表示
- Google Analytics (GA4)にキーワード送信
Flexsearchの設定項目について
一通り使えそうなライブラリやプラグインを試した上で、選んだのは依存性のない全文検索ライブラリであるFlexsearchだった。どういうものか詳しくはREADMEを読む方が早いと思う。
Flexsearchの内部ではREADMEにある図の順番で処理が行われているのだが、

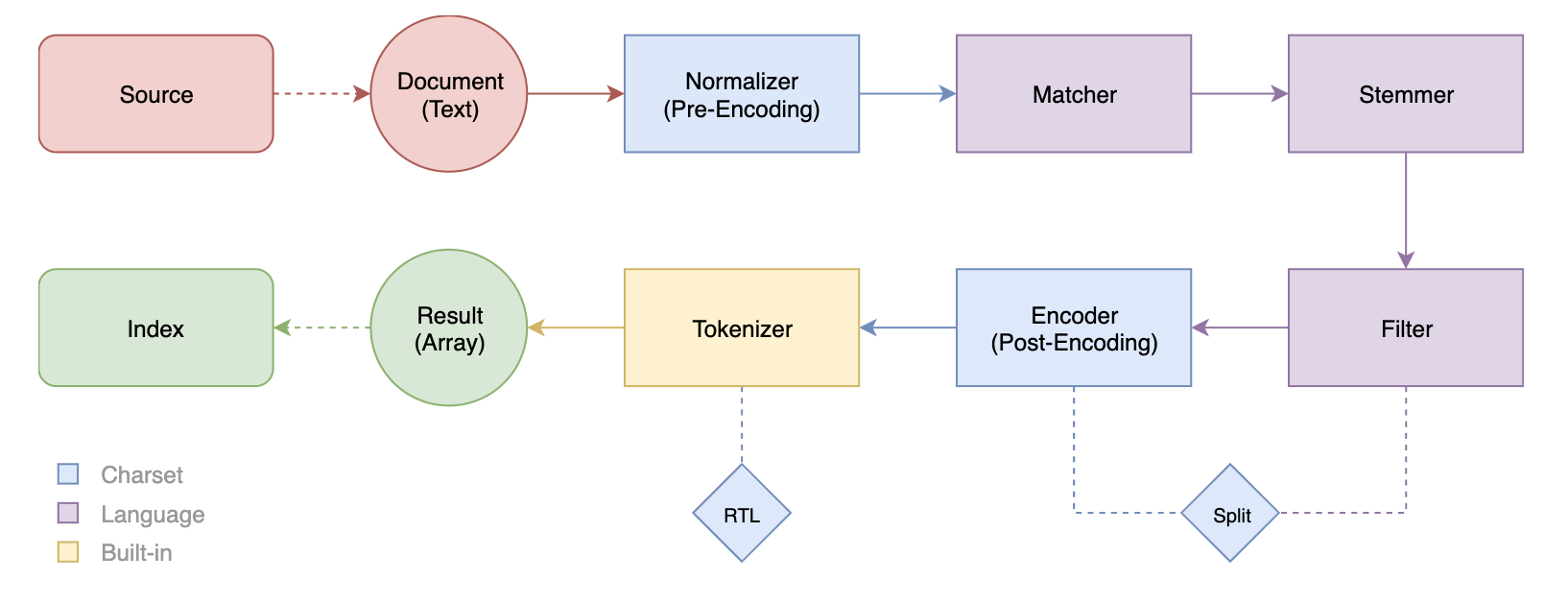
このうちMatcher〜Tokenizerまでオプションで設定ができる。
Normalizer
String.prototype.normalize() による正規化を行なっている。NFD指定なので「正規化形式 D。正準等価性によって分解される」という処理である。その後で、Combining Diacritical Marks(\u0300-\u036f) を除去している。
Matcher
デフォルトでは指定されていないが、設定すると指定した文字でマッチさせることができるようになる。
例えば、{ぬこ:"猫"} のように設定すると内部で処理されて /ぬこ/g という正規表現に変換され、置換対象となる。これによって「ぬこかわいい」という文字が「猫」というクエリでもヒットするようになる。設定は相互に効果があるので、「吾輩は猫である」が「ぬこ」でもヒットするようになる。
世のスラング全てを設定することは困難だが、使用するサイトで使われている用語を設定しておくと検索しやすくなると思う。
Stemmer
語幹による検索に対応させる設定。
英語だと、donationでdonateにもヒットさせるため、{"ation": "ate"} が設定されていたり、
brightnessから接尾語を削除する { “ness”: “” } といった設定がされている。
これが内部で処理されると /(?!\b)nation(\b|_)/g といった正規表現に変換される。
日本語だと「動詞は語幹を漢字で表し、活用語尾をひらがなで書く」といったルールに則ればある程度は機械的に処理することができると思うが、内部処理で \b (単語境界)を使用されているので、stemmerで日本語を設定してもマッチすることはない。
英単語は日本語文章でも混じることがあるので、この設定が全く無意味というわけではない。
Filter
単語のブラックリスト。
この前にcollapseという処理によって同じ文字が連続しないように変形されている。
これはencoderオプションをadvancedかextraにした場合に有効になる機能で、「uuunityyy」で 「unity」がヒットするようになる。
それからsplitで分割されて配列となる。
デフォルトでは区切り、記号、句読点、制御文字で分割される。
その分割された文字列に対してfilterがかけられる。
指定した文字列が分割後の配列に存在していれば配列から除去される。
英語だと「a」や「the」といったそれ単体では意味を持たない単語が設定されている。
日本語のような区切りのない文章が主体だと、分割された文字列が長くなるので、単語に対してフィルタを設定してもほとんど機能しない。
Encoder
Normalizer〜Filterまでの処理と追加の処理をする。
オプションの設定で追加処理が増えていくが、全てアルファベットに対してのことである。
| Option | 説明 | 偽陽性 | 圧縮 |
|---|---|---|---|
| false | エンコードをオフにする | × | 0% |
| default | 大文字と小文字を区別しないエンコーディング | × | 0% |
| simple | 大文字と小文字を区別しないエンコーディング 文字セットの正規化( àáâãäå→a) | × | 〜3% |
| balance | 大文字と小文字を区別しないエンコーディング 文字セットの正規化 リテラル変換 | × | 〜30% |
| advanced | 大文字と小文字を区別しないエンコーディング 文字セットの正規化 リテラル変換 音声の正規化 | × | 〜40% |
| extra | 大文字と小文字を区別しないエンコーディング 文字セットの正規化 リテラル変換 音声の正規化 Soundex変換 | ○ | 〜65% |
| function() | function(string):[words] を介したカスタムエンコーディング |
この処理はsearchメソッドに渡したクエリに対しても行われる。
Tokenizer
文字列を分解してインデックスに登録する。デフォルトではstrictになる。
関数を渡すこともできるが、Promiseは未対応である。
設定によってどの部分が登録されるのかが決まり、範囲を広げるほどにメモリも食う。
| オプション | 説明 | 例 | メモリ係数 (n = 単語の長さ) |
|---|---|---|---|
| strict | 単語全体にインデックスをつける 完全一致のみヒットする | [吾輩は猫である] | * 1 |
| forward | 順方向で段階的ににインデックスをつける 「である」ではヒットしない | [吾輩]は猫である [吾輩は猫]である | * n |
| reverse | 両方向で段階的ににインデックスをつける 「猫で」ではヒットしない | [吾輩]は猫で[ある] 吾輩は[猫である] | * 2n – 1 |
| full | 可能な全ての組み合わせにインデックスをつける どの部分でもヒットする | 吾[輩は]猫である 吾輩[は猫で]ある | * n * (n – 1) |
| function() | function(string):[words] を介したカスタム分割 |
検索の体感はfullが一番しっくりくるが、reverseくらいにとどめておくのが無難そう🤔
キーワードを抽出したJSONを生成
Flexsearchは文字列や文書を登録するとインデックスを生成して検索できるようにしてくれるのだが、日本語だと前述の処理の影響を受けてそのまま登録しただけでは検索が思ったように機能しない。
英語のライブラリなんだから仕方ないが残念。
一応CJKに対応させる方法がないこともないんだけど、言葉の意味関係なくぶった切っただけではイケてる検索結果を得ることはできなかった。
なので日本語の形態素解してキーワードとなりえる文字を抽出して、それをインデックスに登録することにした。その処理をKuromoji.jsでやるのだが、結構処理が重いのでGatsbyのビルドとは別にやっつけて結果をJSONに保存しておくことにした。
全文はGistに。
md-search-index.mjs
Markdownファイルの読み込み
これを書いたNode.jsバージョンは16.6.1です。
/src/data/blog にMarkdownファイルがあるとして、ファイルの中身はこのようになっている。
---
id: 1
title: 記事タイトル
date: '2016-10-12T10:00:00+09:00'
author: yamada_taro
description: 手動生成の抜粋
thumbnail: ../images/blog/1/thumb.jpg
tags:
[
'タグ1',
'タグ2',
]
---
ここから本文
著者情報は /src/data/json/author.json にJSONファイルで登録してある。
[
{
"id": "yamada_taro",
"name": "山田 太郎",
"name_reading": "Yamada Taro",
"description": "著者の説明",
"thumbnail": "../images/author/yamada_taro.png",
"twitter": "",
"qiita": "",
"github": ""
}
]
キーワード生成に必要なこれらのファイルを読み込む。
import { readdir, readFile, writeFile } from 'fs/promises'
import path from 'path'
const DIRECTORY_PATH = 'src/data/blog'
const AUTHOR_JSON_PATH = 'src/data/json/author.json'
const files = await readdir(DIRECTORY_PATH, { withFileTypes: true })
const filterFiles = files.filter((file) => file.isFile())
const author = await readFile(path.resolve(AUTHOR_JSON_PATH))
const authorJSON = JSON.parse(author.toString('utf8'))
Markdownファイルのパース
読み込んだファイルを処理する。
for (let i = 0; i < filterFiles.length; i++) {
const file = filterFiles[i]
documents.push(await parseMarkdownFile(file, authorJSON))
}
Markdownのパースは gray-matter を使った。
contentは remove-markdown でマークダウン記法を取り除いておく。
import removeMarkdown from 'remove-markdown'
import grayMatter from 'gray-matter'
// ...
async function parseMarkdownFile(file, authorJSON) {
const fp = path.join(DIRECTORY_PATH, file.name)
const markdown = await readFile(fp)
const matter = grayMatter(markdown)
const content = removeMarkdown(matter.content)
const author = authorJSON.find((auth) => auth.id === matter.data.author)
// ...
gray-matterによってfrontmatterが取れるので、必要なものをオブジェクトに入れておく。
const document = {
id: matter.data.id,
title: matter.data.title,
date: matter.data.date,
author: author?.name,
tag: matter.data.tags,
keywords: '',
}
キーワード抽出する文字列をくっつけといてkuromojiに投げる。
import { tokenize, KuromojiToken } from 'kuromojin'
//...
const str =
`${matter.data.title}\n\n` +
content
const tokens = await tokenize(content, {
dicPath: path.resolve(`./src/data/dict`),
})
document.keywords = createKeywords(tokens)
キーワード生成
createKeywordsで、キーワードとして使えないテキストの分別と、より検索しやすくするための変換をやっている。
フィルタで、名詞・動詞・形容詞、記号と空白以外、2文字以上というテキストだけ通した上で、
動詞の基本形・連用形・仮定形を弾く。
/**
* キーワードのフィルタ
*/
function tokenFilter(token) {
if (
!['名詞', '動詞', '形容詞'].includes(token.pos) ||
/^[!-/:-@[-`{-~、-〜”’・.,_\s\u02B0-\u02FF\u2010-\u27FF\u3001-\u303F\uFF01-\uFF0F\uFF1A-\uFF1E\uFF3B-\uFF40\uFF5B-\uFF65]+$/g.test(
token.surface_form
) ||
token.surface_form.length < 2
) {
return false
}
switch (token.pos) {
case '名詞':
case '形容詞':
return true
case '動詞':
return !['基本形', '連用形', '仮定形'].includes(token.conjugated_form)
break
}
}
そうして選別されたキーワードを重複しないように配列に追加する。
読み(reading)はカタカナなので、ひらがなに変換したものを入れておいた。
// 表層形
if (!allTokens.includes(token.surface_form)) {
allTokens.push(token.surface_form)
}
const reading = token.reading || token.surface_form
// ひらがな変換
const hira = reading.replace(/[\u30A2-\u30F3]/g, (m) =>
String.fromCharCode(m.charCodeAt(0) - 96)
)
// 基本形
if (
token.surface_form !== token.basic_form &&
token.basic_form !== '*' &&
!allTokens.includes(token.basic_form)
) {
allTokens.push(token.basic_form)
}
// ひらがな
if (token.surface_form !== hira && !allTokens.includes(hira)) {
allTokens.push(hira)
}
JSONファイルに書出し
キーワードを含めたドキュメント情報の配列をJSONに書き出せば完成。
const DIST_FILE_PATH = 'src/data/flexsearch_index.json'
// ...
await writeFile(
DIST_FILE_PATH,
JSON.stringify({
documents,
})
)
Gatsby Node APIでJSONをpublicにコピー
Gatsbyのpublicはバージョン管理対象外になってるので、srcにJSON作っといてビルドの時にコピーされるようにする。
この処理は onPostBootstrap でやっておく。
import { copyFile } from 'fs/promises'
// ...
const onPostBootstrap: GatsbyNode['onPostBootstrap'] = async () => {
try {
await copyFile(
'src/data/flexsearch_index.json',
'public/flexsearch_index.json'
)
console.log('copy success flexsearch_index.json')
} catch (e) {
return console.error(e)
}
}
Gatsby Browser API でキーワードをFlexsearchに登録
onClientEntry で Flexsearchを設定して、windowに格納しておく。
import { Document } from 'flexsearch'
export function onClientEntry() {
fetch(`${__PATH_PREFIX__}/flexsearch_index.json`)
.then((response) => {
return response.json()
})
.then(({ documents }) => {
// Flexsearch
const index = new Document({
preset: 'match',
tokenize: 'reverse',
document: {
index: ['keywords', 'author'],
store: ['author', 'date', 'title'],
},
})
// インデックスに追加
documents.forEach((doc) => {
index.add(doc)
})
window.__FLEXSEARCH__ = index
})
.catch((err) => {
console.error(err)
})
}
DocmentはJSONを格納できるので、事前に生成しといたJSONをそのままaddで登録する。
オプションでどのフィールドにインデックスを貼るのか、ストアを利用するのかなど設定しておく。
Searchコンポーネントで検索を実行、結果表示
windowにFlexsearchを格納しておいたので場所を問わず呼び出すことができる。
Input要素の change イベントとかで、入力された値をFlexsearchのsearchメソッドに渡す。
オプションでenrichを有効にすると、デフォルトではIDだけの検索結果にJSONが含まれるようになる。
const [query, setQuery] = React.useState('')
const [results, setResults] = React.useState([])
const handleChange = (e: React.ChangeEvent<HTMLInputElement>) => {
setQuery(e.target.value)
if (!e.target.value || /^\s+$/.test(e.target.value)) {
setResults([])
return
}
const searchData = window.__FLEXSEARCH__.search(e.target.value, {
enrich: true,
})
if (!searchData) {
setResults([])
return
}
// ...
searchの戻り値は、Documentでは初期化時に設定したdocument.indexのフィールドごとになり、JSONも該当したものが全てresultに格納されるので、重複を弾いた配列を作る。
type StoreDoc = {
author: string
date: string
title: string
}
type SearchResult = {
id: number
doc: StoreDoc
}
// ...
const documents = searchData.reduce(
(acc: SearchResult[], cur: { field: string; result: [] }) => {
cur.result.forEach((result: SearchResult) => {
if (!acc.find((a: SearchResult) => a.id === result.id)) {
acc.push(result)
}
})
return acc
},
[]
)
setResults(documents)
配列できたらループで表示する。
{results.map(({ doc, id }: SearchResult) => {
<div key={id}>
{doc.title}
{doc.author}
{doc.date}
</div>
})}
mecab辞書をkuromoji辞書に変換
一通り実装して動作確認していた時に、Unityについての記事に3Dがタグで設定されているのに検索に引っ掛からず、キーワードにすらなってないことに気づいて愕然とした。
何かやらかしたのかと思ったが、辞書に登録がなくて抽出できてないのだった。
そこで、新語に対応している mecab-ipadic-neologd 辞書をkuromojiで利用することにした。
- git-lfsとxzとnkfのインストール
brew install git-lfs xz
(既に入ってたらスキップ) - kuromoji-js-dictionary をクローン、
npm install - インストール終わったら
./bin/run
(権限で弾かれる場合はsudoつける) - ビルド終わるまで待つ
- distファイルの中身をGatsbyのsrc以下の任意の場所にコピー
- Kuromoji.jsのdicPathオプションで5のディレクトリを指定
nologd辞書の追加でキーワード生成し直したら3Dも登録されるようになった。やったね。
最新版の辞書or追加辞書を利用する場合
dictディレクトリにmecab-ipadic-2.7.0-20070801.tar.gz が存在してないか、あってもサイズが12MBほどなければ、正しくダウンロードできてないのでビルドに失敗する。
今のところmecab-ipadicは20070801で更新が止まってるようだが、もし更新があった場合はダウンロードした辞書をdictディレクトリに配置すれば良い。
- mecabのサイトからIPA辞書をダウンロード
- ダウンロードした mecab-ipadic-*.tar.gz を kuromoji-js-dictionary/dict に移動
neologdの辞書を更新したり追加したりする場合は、neologd-seed ディレクトリに配置する。
- mecab-ipadic-neologd をクローン
- mecab-ipadic-neologd/seed の中身を kuromoji-js-dictionary/neologd-seedにコピー
- kuromoji-js-dictionary に cd して
npm install
辞書を変更したら npm run xz && npm run tar で変換する。
UTF-8辞書の対応
neologd辞書はUTF-8なのでそのまま変換にぶち込むとデコードでEUCにされて文字化けする。

reader.js の94行目くらいにあるデコードを変更。
const isUtf8 = require('isutf8')
// L94
rl.on('line', (buf) => {
if (isUtf8(buf)) {
obs.next(iconv.decode(buf, 'utf8'));
} else {
obs.next(iconv.decode(buf, 'euc-jp'));
}
});
辞書変換し直して文字化け治ってればOK。

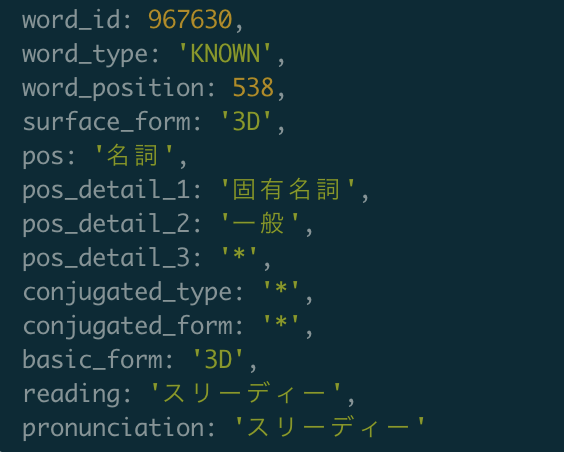
キーワードを含むセンテンスの抽出
kuromojiは単語が存在した位置も返すので(上の画像のword_position)、それを利用して前後を切り取ればキーワードを含んだ短いテキストを生成することができる。
const sentence = str.slice(
Math.max(0, token.word_position - 30),
Math.min(token.word_position + 30, str.length)
)
できるけどJSONサイズもメモリも増大するので、フロントでやることではない🙄
エラー
Error downloading object: dict/mecab-ipadic-2.7.0-20070801.tar.gz (b62f527): Smudge error: Error downloading dict/mecab-ipadic-2.7.0-20070801.tar.gz (b62f527d881c504576baed9c6ef6561554658b175ce6ae0096a60307e49e3523): batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access.
上限に達してて辞書がダウンロードできなかった。
node_modules/rxjs/Subscriber.js:246
[Error: ENOENT: no such file or directory, open '...../kuromoji-js-dictionary/.tmp/matrix.def'] {
errno: -2,
code: 'ENOENT',
syscall: 'open',
path: '...../kuromoji-js-dictionary/.tmp/matrix.def'
}
mecab-ipadic-2.7.0-20070801.tar.gz の解凍に失敗している。mecabのサイトからダウンロードする。
The value of "length" is out of range. It must be >= 0 && <= 2147483647. Received 2684354560
読み込んでる辞書に問題がある。エンコードをミスっている可能性が高い。
GA4に検索キーワードを送信する
Google AnalyticsはURLクエリからサイト内検索キーワードを収集するが、モーダルなどを利用していてURLを変化させない場合はキーワードが収集されないので、gtag関数を叩く必要がある。
if (query && window && typeof window.gtag === 'function') {
window.gtag('event', 'view_search_results', {
page_location: window.location.origin,
page_path: window.location.pathname,
page_title: 'サイト内検索',
keyword: query.trim(),
})
}
input要素のchangeイベントとモーダルのcloseイベントの2通りある。
changeイベントだとdebounceやthrottleを使っても入力途中のキーワードが送信されるが、ユーザーが検索を試みたキーワードが全て取得できる。
closeイベントだと入力途中のキーワードは送信されないが、モーダルが閉じた時のキーワードに限られるので、途中でキーワードを変更していた場合は取得できない。

参考
- How to Add Lunr Search to your Gatsby Website
Lunrは日本語に対応しているけどいまいちな動作だった。あと重い - gatsby-plugin-flexsearch
使ってみたけど日本語だと微妙になったので実装だけお手本にした - kuromojin
Kuromoji.jsはPromise未対応なのでこっちを使っている - 【Node.js】kuromoji.js + mecab-ipadic-neologdで形態素解析して遊ぶ
kuromoji-js-dictionaryを知るきっかけになった - Gridsomeでイチからブログを作る – サイト内全文検索機能をつける
フィルタのところ参考にした - MeCab
日本語形素解析の雄 - UTF-8の文字コード表